
TwitterをはじめとしたSNSは、リアルタイム性が高く多様な情報を入手できることから、今日では多くの人が情報収集に利用しています。しかし一部では、間違いや誤解を招く情報があたかも真実の情報として出回っていることも事実です。特に新型コロナウイルスに関しては、こうした情報が社会的混乱を巻き起こす可能性もあります。実際にトイレットペーパーやうがい薬が瞬く間に品薄になったことも記憶に新しく、より信頼性の高い情報が世の中から求められています。こうした状況下でSNSの情報の信頼度を高めるため、NTTデータとDataRobot社は、Twitter全量データとエンタープライズ AIプラットフォームであるDataRobotを活用して、新型コロナウイルスに関するデマツイートの特徴を分析し、その判定モデルの構築に取り組みました。今回はプロジェクトのメンバー4人に、プロジェクトの経緯や展望について伺いました。

中山 忠明
NTTデータ ITサービス・ペイメント事業本部 SDDX事業部 マーケティングデザイン統括部 デジタルマーケティング担当
NTTデータに入社後、開発エンジニアとして金融機関向けのプロジェクトに従事。その後プロジェクトマネージャーとして、リスクモニタリング領域における開発プロジェクトを複数経験。現在はTwitter全量データを活用したマーケティング戦略立案・分析を製造、金融、食品などさまざまな業種の企業に提供している。趣味はスポーツ観戦とアウトドア。屋外で飲むビールに勝るものはない。

夏 エイチュウ
NTTデータ ITサービス・ペイメント事業本部 SDDX事業部 マーケティングデザイン統括部 デジタルマーケティング担当
中国出身。2019年にNTTデータに入社して以来、Twitter全量データ活用に従事し、幅広い業種の企業をお客さまとし、マーケティング立案、分析やリスクモニタリングなどに携わっている。

笠原 宏太
ビジネスソリューション事業本部 AI&IoT事業部 コンサルティング統括部コンサルティング担当
大学院時代に素粒子物理学を専攻し、CERN(欧州原子核研究機構)で暗黒物質の研究に貢献。博士号取得後、NTTデータに入社し大手製造業様向けのデータ分析案件や、自然言語処理関連の分析案件に従事。DataRobotやNTT研究所開発技術(corevo)を活用し、分析設計~業務への実装までトータルでの支援を行い、定着化を実現してきた。DataRobot認定CFDS(Customer Facing Data Scientist)。

坂本 康昭
DataRobot データサイエンティスト
2005年にテキサス大学にて認知科学博士号取得。スティーブンス工科大学での教授職時代にSNS上での情報共有に関する研究を含む50を超える学術論文を出版、データサイエンスプログラム立上げメンバーとして貢献。2015年に日本に戻り、保険会社でチーフサイエンティストとしてAIのビジネス活用をリード。2017年からDataRobotのデータサイエンティストとして金融、ヘルスケア、製造などさまざまな業界のお客さまをサポート。
新型コロナウイルス発生当初から社会問題化していた情報の信頼性確保
―どのような経緯でこの取り組みが始まったのですか。
中山さん:DataRobot社が提供している新型コロナウイルス分析官向けの無料プログラムを知ったことが直接のきっかけです。以前から、Twitterデータの分析に機械学習モデルを自動で作成してくれるDataRobotを活用できないかと検討していたため、このプログラムを通して利用してみようということになりました。

総務省のレポートでも報告されていますが、SNSは特に若い世代の利用頻度が高く影響力が大きいメディアである一方、真偽不明や誤った情報を見聞きする機会もあります。Twitterはそういった情報に出会う割合が高い一方で、その情報は「真実ではない」といった自浄作用が多く働くメディアでもあります。そのため今回のプログラムを活用して、新型コロナウイルスに関するTwitter上の情報について、DataRobotで信憑性を判定するモデルが作れるのではないかと考えました。
Twitterソリューションを担当する私と夏さんに加え、DataRobotに知見のあるAI&IoT事業部の笠原さんとDataRobot社の坂本さんに協力をお願いし、この研究開発プロジェクトに踏み切りました。

坂本さん:DataRobotは国内外のNPOで利用いただくケースも多く、社会貢献のカルチャ—が根強い社風です。新型コロナウイルス流行下においても、各国で取り組まれている対策をいち早く支援すべく、この分析官向けの無料プログラムの提供を開始しました。現在、プログラムはさまざまなケースで利用されていますが、日本では地域ごとに患者数の推移を予測するなど、医療機関や研究機関で利用いただいているケースが多いです。今回のプロジェクトのような「SNSのデマ情報を判定する」という目的は初めての例でしたが、ぜひ取り組んでみたいと思い、協力させていただくことになりました。
急速な状況変化への対応と、前例のない自然言語解析の試行錯誤
―今回の分析プロジェクトと従来の分析プロジェクトで何か違いはありましたか。
笠原さん:1点目として、新型コロナウイルスは突如発生して急速に状況が変化したものであるため、他プロジェクトと比較して学習データが少量しかありませんでした。AIは過去のデータに基づいて学習を行う技術ですので、データが少ないと予測能力の高いモデルの構築が難しい場合があります。今回の取り組みでは、少量のデータでも汎化性の高いモデルになるようにデータ項目を精査したり、類似するデータを利用したりするなどのアイディアを試行し、最良のモデルを選定していきました。
2点目として、学習データ作成のため、ツイート1件1件に対してデマか否かを我々自身で判断する必要がありました。デマか否かの調査には非常に時間と手間がかかるうえ、判定できた一部のツイートだけを使用してモデルを作っていくことになるので、モデルに偏りが出ないよう細心の注意を払って進めていきました。
坂本さん:実は最終的に採用したモデルでは、特徴量にツイートの本文は含まれていません。Twitterでは、アカウント名、プロフィール文、リツイート数など、本文以外にもさまざまな情報が取得可能なので、それらの情報によって信憑性を判断したということです。本文以外の情報でも精度の高いモデルの構築ができるという結果には、私もとても驚きました。
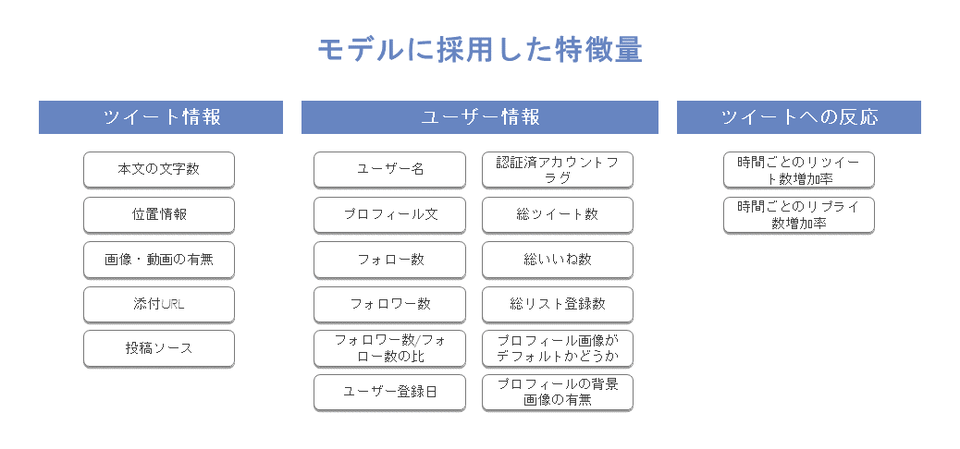
中山さん:一口にデマ情報と言ってもさまざまなパターンがあって、意図的にデマを投稿したものだけではなく、本人は有益だと思っている情報を広めたいというポジティブな気持ちで投稿したものが結果的にデマであったケースもあります。
また、短期間でも状況が刻々と変わっていく新型コロナウイルス流行下では、デマ情報の中身もさまざまありました。トイレットペーパーがなくなるといったものや、新型コロナの発生場所に関するものや致死率・生存率に関するもの、新型コロナに効果のある食べ物、治療法など多岐にわたります。
こうした多種多様なパターンのデマ情報に対して正確に信憑性を判断できる、汎用性が高いモデルになるように試行錯誤しました。
坂本さん:2011年に東日本大震災が発生した際にも、私は同様にデマ情報を判定する研究をしていたことがあります。当時も、震災発生直後から状況が変化するにつれて、人間の行動パターン、そしてデマ情報に変化が見られました。今回の新型コロナウイルスについても、この先科学的な新事実が判明することなどがあれば、人々の行動パターンが大きく変化するかもしれません。その場合一度学習したモデルの精度が下がるということもありますので、学習データを更新して再学習を行い、モデルを更新していく作業が必要となりますね。
―実際の分析を進める中で苦労したことはありますか。
夏さん:DataRobotでTwitterデータのような非構造化データを解析した事例があまりなかったため、さまざまな課題に1からぶつかっていかなければなりませんでした。モデリングはAIが自動で行う領域ですが、学習データ準備や特徴量を選定するプロセスは、人の知見や地道な作業も必要になってくるところなので特に苦労しました。
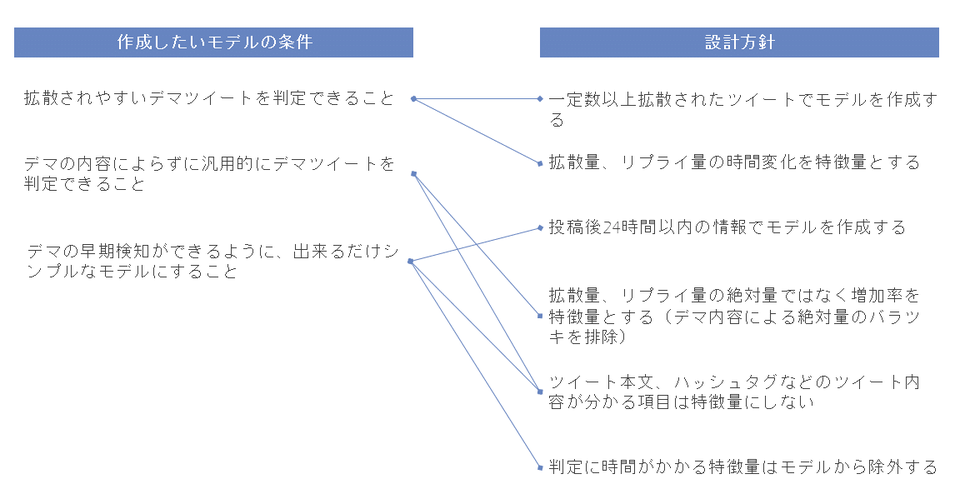
最初はどんなモデルをめざすのかをあまり決めず、関係がありそうな特徴量をすべて学習データとして投入してみたのですが、それではあまり精度の高いモデルができませんでした。そこで、あいまいになっていた「理想とするモデル」の要件をきちんと定めるという段階に立ち戻りました。
今回は、理想とするモデルを「拡散されやすいデマを判定できること」「デマの内容によらず判定できること」「早期検知ができるようシンプルなモデルであること」の3つの要件で示しました。この要件に沿って、「精度が高いモデルに繋がる特徴量」の仮説を具体化、実際にパターンをいくつか設計し比較検討をしていきました。
この方法が功を奏し、最終的には設定した中でもっともシンプルかつ精度が高かったものを採用することになりました。AIがモデリングをしてくれるとは言え、要件をきちんと整理してある程度仮説を持って進めることが大事だと感じました。
笠原さん:夏さんの言う通り、AIプロジェクトでは、初めに仮説を立て、分析設計をきちんと行い、実際に検証するというサイクルを何度も繰り返して実運用可能なモデルに近づけていきます。
仮説立案時には、やはり人が目で見て考えていく必要があります。たとえば今回の場合では、信憑性の高いツイートの特徴として、アカウントの紹介文に「公式」というキーワードやURLが入っているものが多いのではと考えて、そこから紹介文にこれらの要素が入っているかどうかという特徴量を導きだしました。
次サイクルの方針が決まったら、それに合わせて学習データを準備しますが、特にテキストデータはこの作業が大変なため、実際に作業をしてくれた夏さんは非常に苦労したと思います。
坂本さん:テキストデータはやはり前処理が非常に大変ですよね。テキスト解析は数値データと異なり、文章を単語に分けたりキーワードを抽出したりといった処理が必要になります。これらの処理はDataRobotが自動で行ってくれるのですが、最初のステップとして集めたデータをAIが処理できるよう、事前にデータをメンテナンスする作業が必要となります。
作業を担当されていた夏さんは苦労したと思いますが、これまでさまざまなプロジェクトを見てきた私の所感としては、今回のプロジェクトではかなりスムーズに仮説立案から検証のサイクルを回すことができていたように感じました。AIを利用した分析では最初から完璧を求めず、サイクルを回していくうちに少しずつ改善していくことが重要ですが、当初からその姿勢で取り組まれていたのではないでしょうか。
笠原さん:DataRobotが仮説立案から検証までのサイクルを特に回しやすいプロダクトであることも要因の一つだと思います。モデル構築・精度評価だけでなく、どんな特徴量が有用か、特徴量がどんな値だとデマなのか、といった情報も自動で出力されるため、次のサイクルで何をすべきか簡単に検討することができます。DataRobotがなければ、毎サイクルこれらを実施するためのプログラミングが必要なのですが、そこを自動化してくれるのは本当に画期的で、人間が本当にやるべき仮説立案や分析設計に注力できると思います。
夏さん:仮説立案から検証までのサイクルを回すたびにミーティングを行い、トラブルや課題について笠原さんや坂本さんにアドバイスをいただいていたおかげで、苦労はあったのですが確かに毎回前進している実感がありました。DataRobotは、GUIで操作しやすく簡単にモデル構築を自動で行ってくれる点が強みだと聞いていましたが、今回の取り組みを通して実感しました。
Twitter×DataRobotで広く使ってもらえるソリューションをめざしたい
―この取り組みを今後どのように発展させていきたいですか。
中山さん:TwitterをはじめとしたSNSは現代の人々にとって重要な情報ソースになっていて情報量も膨大です。情報の信憑性チェックという点では、ひとつひとつの情報を人手でチェックすることは大変ですが、今回の取り組みで得られた知見をもとにAIを活用することで、例えば膨大な情報を機械的にスクリーニングすることが出来るようになると考えており、いままで捌ききれなかった量の情報を短時間で処理できるようになっていくと思います。
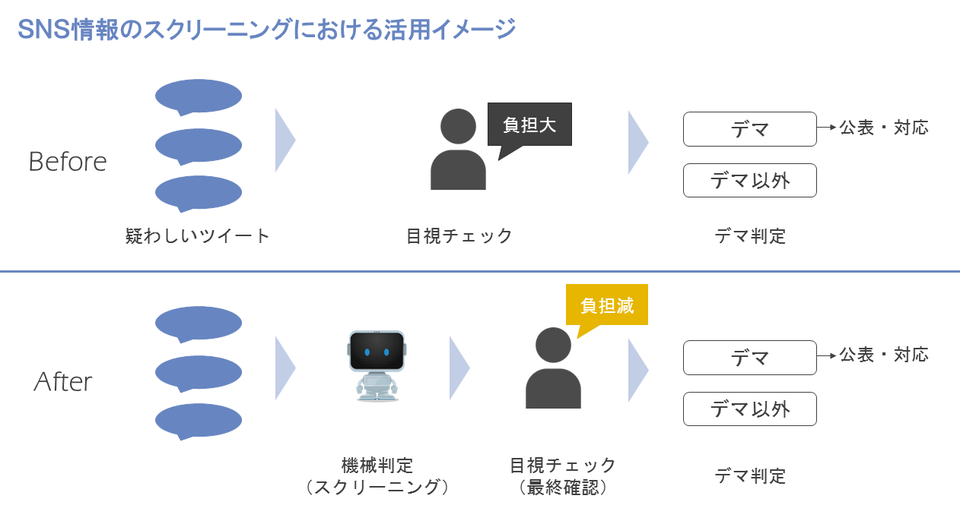
夏さん:Twitterデータは本文以外にも投稿者情報や位置情報、画像情報などさまざまな情報を含んでいます。今回の検証では、位置情報、画像情報などは特徴量として活用できていないですが、それらの特徴量を組み合わせることでまた新しいモデルを作ることができるので、試していきたいと思います。
中山さん:今回取り組みんだことで、ほかにもさまざまな分野でTwitter×DataRobotを活用できるのではないかと感じました。今回は社会貢献の目的が強いプロジェクトでしたが、DataRobotでは需要予測などの時系列分析もできると伺っているので、企業のマーケティングへの活用なども今後ぜひ取り組んでみたいですね。DataRobot社と一緒にTwitterデータを活用したソリューションをつくり広めていくことをもめざしたいです。
笠原さん:今回苦労したデータの前処理や有用な特徴量を生成する処理をはじめ、今回の取り組みのノウハウが体系化されると、ソリューション化に一歩近づくかもしれないですね。特にBtoCビジネスではTwitter上に製品やサービスに関するユーザーのコメントが多く含まれるため、利用シーンが多そうです。
坂本さん:Twitterから得られるデータは、リアルタイム性があるという点でも有益ですので、ソリューション化すればさまざまなユースケースが考えられると思います。例えばDataRobotに投入する前のデータの前処理から DataRobotからのアウトプットを意思決定につなげるまでの一連の流れがソリューション化されていれば、 Twitter×DataRobotを利用できるシーンが増えていくのではないかと思います。
新着記事を探す


キーワードから記事を探す
- #キャッシュレス
- #ソーシャルメディア
- #スポーツ
- #OMO
- #CRM
- #顧客ロイヤリティ
- #顧客エンゲージメント
- #One to Oneマーケティング
- #ポイント管理
- #顧客管理
- #カスタマーエクスペリエンス
- #デジタル店舗
- #人手不足
- #レジ無し店舗
- #ウォークスルー店舗
- #デジタルマーケティング
- #デジタルトランスフォーメーション
- #お客様コミュニケーション
- #チームビルディング
- #データ活用・分析
- #プラットフォーマー
- #エコシステム
- #ワークショップ
- #お客様接点
- #Microsoft
- #CAFIS Explorer
- #デジタルビジネス
- #ビジネスデザイン
- #サービスデザイン
- #振り返り記事
- #DX人材育成
- #NRF2020
- #NRF2023
- #ニューリテール
- #ポイントサービス
- #UXデザイン
- #リアル店舗
- #在宅勤務
- #テレワーク
- #働き方改革
- #遠隔接客
- #アフターコロナ
- #ウィズコロナ
- #CoE
- #SEO対策
- #UI改善
- #Web広告
- #テクノロジ・トレンド
- #ロボット活用
- #消費行動
- #アジャイル
- #ビジネスデザインスプリント
- #インフルエンサー
- #XR
- #VR
- #AR
- #MR
- #AI
- #アジャイル開発
- #プロダクトオーナー
- #アドテック東京
- #ビジネスフェア
- #BtoBオウンドメディア
- #異業種連携
- #銀行代理業
- #AI・IoT
- #医療・ヘルスケア
- #フードテック
- #パーソナライズ
- #リテールテックJAPAN
- #V-BALLER
- #プロダクトマネージャー
- #メンタリング
- #サービス共創
- #ギャンブル依存症
- #社会課題解決
- #Athena
- #マーケティングROI
- #MA
- #SCビジネスフェア
- #用語解説
- #組織変革
- #Marketing
- #奥谷孝司
- #マーケティングの新しい基本
- #顧客時間
- #VivaTech
- #メタバース・NFT
- #D2C












