マーケティングデータ分析をスモールスタート!Amazon Athena徹底解説!
デジタルマーケティングでは欠かせない大量の顧客データ分析。大量のコンピューティングリソースを使うため、高額なマシンを導入できずになかなか分析に取りかかれない方もいらっしゃるのではないでしょうか。本記事ではこうしたマーケティングデータ分析や分析環境構築に携わるエンジニア向けに、分析した量に応じて課金されるAmazon Athenaを使った分析環境についてご紹介します。
執筆者紹介

加賀谷駿
株式会社NTTデータ ITサービス・ペイメント事業本部 スマートライフシステム事業部 交通・観光統括部 デジタル推進チーム 主任
前職ではアプリケーションエンジニアとして交通ビッグデータのWeb分析システムをAmazon Athenaを使用して開発、Amazon社との合同発表。NTTデータ入社後もAmazon Athenaを使用したデータ分析基盤の構築やTableau Serverの構築、運用。またデータサイエンティストとして鉄道における訪日外国人の分析や航空通信データの分析を実施する等、分析基盤構築からビジネス活用まで幅広く担当。
AWSでのデータウェアハウスサービス比較
まず、AWS上でビッグデータ分析を実現するサービスはいくつかありますが、代表的なものとしてはAmazon RedshiftとAmazon Athenaのふたつが挙げられます。大きな特徴の比較は以下の通りです。
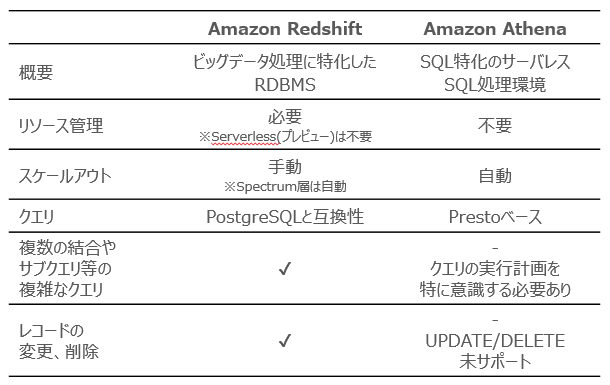
Amazon Redshiftとはビッグデータの処理に特化したデータウェアハウスサービスです。他のデータウェアハウスサービスと比べて、複雑なクエリやデータの更新/削除にも対応しているためデータの加工がしやすいといったメリットがあります。一方で、高スペックなマシンを確保する必要があるため高コストが求められます。特にデータウェアハウスの利用頻度が高くないうちはリソースを使い切ることができず、費用対効果が低くなることも少なくありません。
※2022年2月現在、Amazon RedshiftにはAmazon Redshift Serverlessと呼ばれるオプションがプレビュー版として公開されています。マシンの利用頻度が低いけれどもRedshiftを検討したい場合にはこちらのオプションも候補の一つとなります。
Amazon Athenaはユーザーがマシンを管理する必要のないサーバーレスアーキテクチャのサービスです。ユーザーはSQLクエリを発行するだけでAWSが必要な分のコンピューティングリソースを自動的に割り当ててくれます。料金体系もRedshiftのインスタンスの利用時間に応じた課金とは異なり、クエリ実行時のスキャンサイズに応じて課金されます。クエリを実行しなければS3ストレージの料金以外課金されません。
スモールスタートでマーケティングデータ分析を始めたい場合、使った分だけしか課金されず、またマシンの管理も不要で運用コストも抑えられるAmazon Athenaを利用するのがおすすめです。ここからは、Amazon Athenaを使った費用対効果の高いデータ分析基盤について、少し詳しくご紹介していきます。
Amazon Athenaを使ったデータ分析基盤の構成例
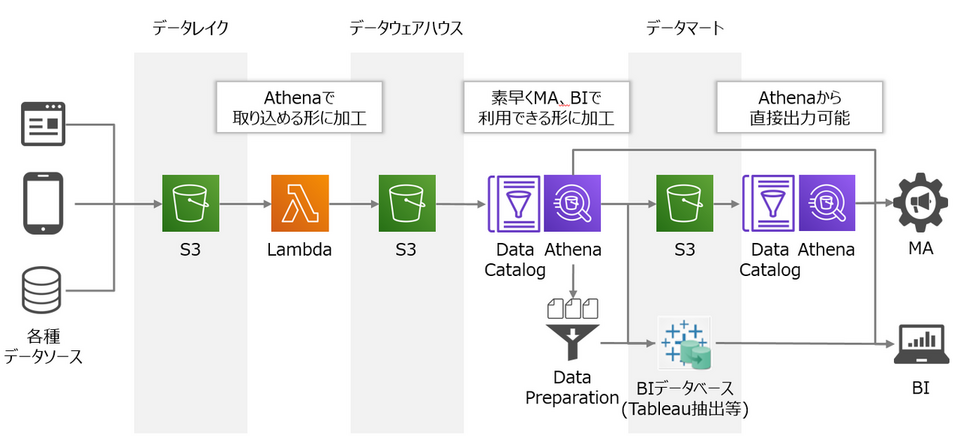
Athenaを使ってデータ分析基盤を構築するにはデータの更新、管理、運用を考慮したアーキテクチャが重要になってきます。よく使われるのが「データレイク」「データウェアハウス」「データマート」の三層構造です。データレイクでは収集したデータを生データのまま保管し、データウェアハウスではAthenaやRedshiftで集計可能なフォーマットにデータを加工していきます。そしてデータマートではMAやBIなどで素早く利用できるように一部データを集計して配置します。
ここからの解説は、こちらでご紹介した3層のデータ分析基盤の構成例に基づいて、進めていきます。
AWS Lambdaを使ったデータの前処理
Athenaで分析するには、データレイクにある生データをAthenaで読み込める形に加工する必要があります。いわゆるデータの前処理です。AWSにはデータの前処理を行うサービスとしてAWS Glue ETLがあります。このサービスもサーバーレスで利用でき、前処理に必要な機能が一通り揃っているため便利なのですが、いざ構築してみると料金が高くなることがあります。ここでは別の実現方法として、AWS Lambdaを使ったデータの前処理を検討してみましょう。

LambdaもGlue ETLと同様サーバーレスのサービスですが、Glue ETLよりも細かくリソース設定することができるコード実行サービスです。実行可能なプログラミング言語は、データの加工でよく使われるPythonや、ファイル操作が容易なPowerShell、また任意のプログラミング言語をRuntime APIを使って実現することも可能です。これらの言語をLambda上で実行すれば、データの整形、加工を行うことができます。
料金体系はGlueの分単位の課金とは異なり、ミリ秒単位のコンピューティング時間で課金されます。ジョブごとの実行時間が短い場合、Lambdaで構築することでGlueよりも料金を抑えることが可能です。またLambdaには無料枠が存在します。実際、多くのお客さま企業の環境でAWS無料枠の範囲でデータの前処理を実現できています。
一方でLambdaの制限として最大15分までしか連続実行ができません(Glueは最大48時間まで実行できます)。Lambdaでデータの前処理を実現するには日次でジョブを実行するなど、15分で収めるような工夫が必要になってきます。
その他の機能に関してはLambda、Glueどちらも必要な機能は揃っています。エラー時の処理分岐やS3配置をトリガーにした実行、StepFunctionsを使った複雑な処理フローや状態管理も可能です。
AWS Glue Data Catalogを使ったデータカタログ管理
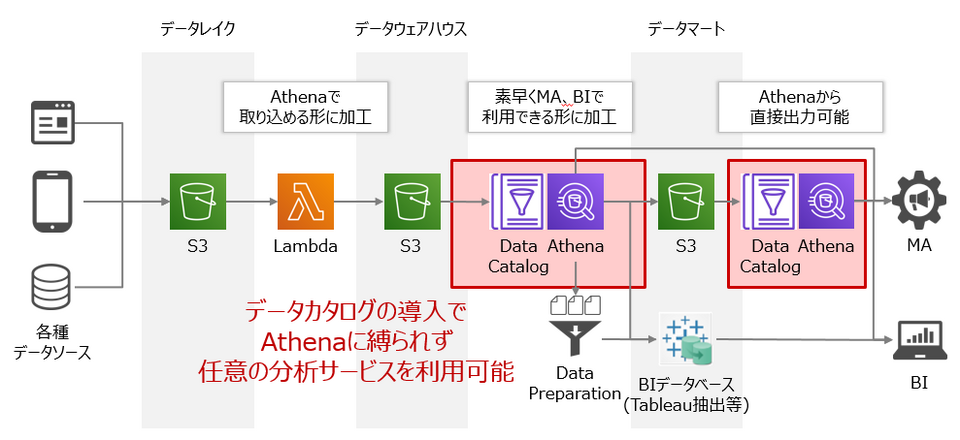
データの前処理をしてS3に配置されたデータに対し、続いてAthenaに取り込むためにテーブル定義などのデータカタログを作成する必要があります。これらのデータカタログはAthena上に直接作成し保存することも可能ですが、AWS Glue Data Catalogと呼ばれるデータカタログ管理サービスを使うことで、AthenaだけでなくRedshiftやEMRといった他のデータ分析サービスとも連携ができます。
Athenaを使う上でGlue Data Catalogの利用は必須ではありませんが、コンピューティング部分のAthenaとストレージ部分のS3が疎結合を保てるようになり、将来的にAthena以外のデータ分析サービスと連携したくなったときに簡単に移行できるようになります。SQLクエリを都度発行する自由分析では、気軽にデータウェアハウスサービスを切り替えながら分析するといったことも可能です。一方で定型分析では、データウェアハウスサービスごとにSQLの書き方が異なるため、SQLクエリが固定化されている定型帳票を気軽に切り替えるといったことは難しいかもしれません。
とはいえ、料金が非常に安く、100万オブジェクト、100万リクエストを越えない限りは無料で利用できるため、まずは使用することをおすすめします。
データマートはAthenaでもサードパーティーでもOK
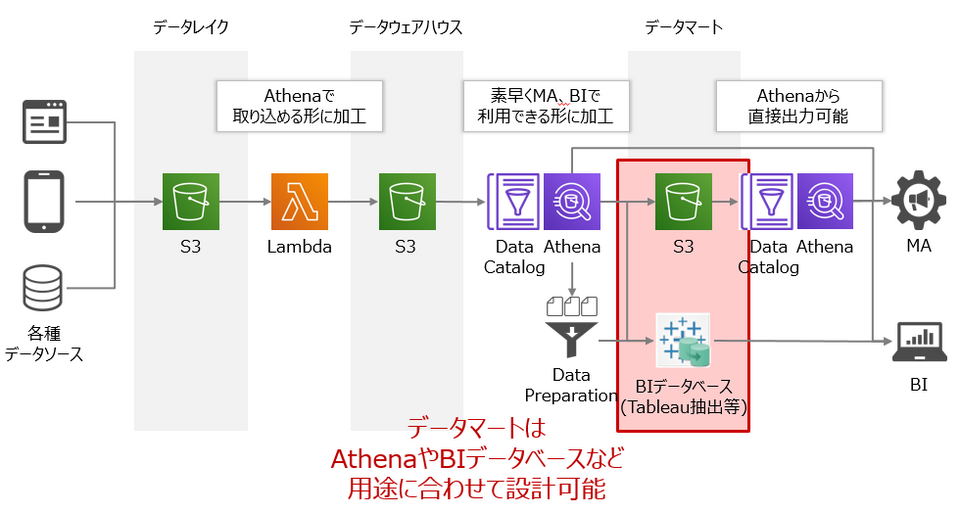
無事データウェアハウスが構築できたら、最後にデータマートを検討します。データマートの構築方法はいくつか考えられますが、ここでは代表的な方法として2つご紹介します。いずれの方法も素早く安価に構築できますので、どちらを選んでいただいても大丈夫です。
ひとつめはデータマートもAthenaで構築する方法です。データウェアハウスで集計した結果をそのままAthena上のテーブルとして保存します。AthenaはJDBCコネクタに対応しているため、さまざまなサードパーティツールからコネクタ経由でAthenaのデータマートに接続可能です。1つのデータマートから複数のツールで接続したい時に便利であることに加え、データウェアハウスでAthenaを構築しているのでデータマートに流用することで容易に構築できます。
ふたつめはサードパーティツール側の機能でデータマートを構築する方法です。例えばBIツールでTableau Serverを使用している場合は、抽出ファイル(.hyper)を使ってTableau内部にデータマートを構築することができます。ワークブックと密に結合した状態で管理させることで、計算フィールドの作成などワークブックに特化したデータソースを作成できます。抽出の設定は「ライブ」から「抽出」にボタン一つ切り替えるだけで容易に実現可能です。
Amazon Athenaを利用する上での重要ポイント
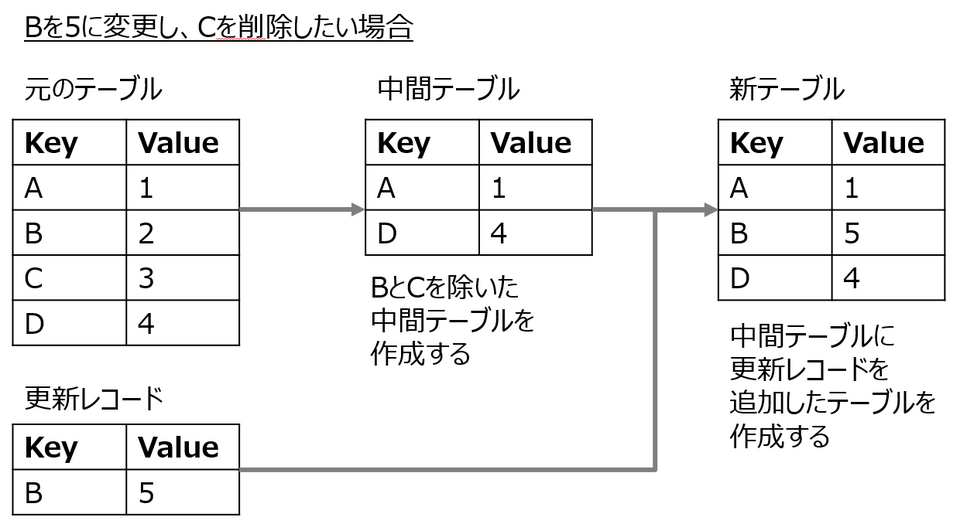
ここまでAthenaの分析基盤の構成についてお伝えしてきましたが、一点利用にあたって重要なポイントがあります。それは、Athenaではレコードの変更(UPDATE)、削除(DELETE)ができないことを考慮したテーブル設計です。
Athena上でレコードを変更するには、対象のテーブルやパーティションを一度削除してからもう一度作成し直す必要があります。図のように更新したいレコードを一度テーブルから取り除き中間テーブルを作成した上で、更新レコードを追加(INSERT)するため、非常に手間がかかります。
なるべくこの手間を減らすための1案として、更新されやすいデータを別テーブルで切り出し、分析時に結合(JOIN)する方法があります。例えば売上明細テーブルに顧客情報が含まれていたとします。顧客情報は転居などで住所や連絡先にどうしても変更が入る可能性があり、そのたびに売上明細テーブルすべてを再作成することは現実的ではありません。こうした場合は、顧客情報を顧客テーブルとして別出ししておき、分析する時に売上明細テーブルと顧客テーブルをJOINすることで、それほど分析パフォーマンスに影響を与えることなく、更新対象のデータを削減することができます。
高速な分析を維持し、更新も実現可能なテーブル設計の検討はAthenaを利用する上でとても重要です。
まとめ:まずはAthenaでデータ分析をスモールスタート!
本記事ではAmazon Athena、AWS Lambda、AWS Glue Data Catalogを使ったデータ分析基盤の構築についてご紹介いたしました。サーバーレスアーキテクチャの特徴を活かし、早い(自動スケーリング)、安い(費用対効果の高い課金体系)、楽(運用不要)の3拍子を実現することができます。
本アーキテクチャの課題として、Athenaでは複雑なクエリやデータの更新/削除ができないという制限がありますが、テーブル構成を工夫することでデメリットを回避、軽減することが可能です。Glue Data Catalogを導入することでAthena以外のデータウェアハウスサービスへの移行も容易となりますので、最初はAthenaを利用しスモールスタートに分析を始め、ある程度組織に分析が定着しデータウェエアハウスの利用者が増えたらより柔軟に分析可能なRedshiftに移行するのでもよいでしょう。
次回、近年注目の高まるSnowflakeについての解説編も検討しておりますのでお楽しみに!
新着記事を探す


キーワードから記事を探す
- #キャッシュレス
- #ソーシャルメディア
- #スポーツ
- #OMO
- #CRM
- #顧客ロイヤリティ
- #顧客エンゲージメント
- #One to Oneマーケティング
- #ポイント管理
- #顧客管理
- #カスタマーエクスペリエンス
- #デジタル店舗
- #人手不足
- #レジ無し店舗
- #ウォークスルー店舗
- #デジタルマーケティング
- #デジタルトランスフォーメーション
- #お客様コミュニケーション
- #チームビルディング
- #データ活用・分析
- #プラットフォーマー
- #エコシステム
- #ワークショップ
- #お客様接点
- #Microsoft
- #CAFIS Explorer
- #デジタルビジネス
- #ビジネスデザイン
- #サービスデザイン
- #振り返り記事
- #DX人材育成
- #NRF2020
- #NRF2023
- #ニューリテール
- #ポイントサービス
- #UXデザイン
- #リアル店舗
- #在宅勤務
- #テレワーク
- #働き方改革
- #遠隔接客
- #アフターコロナ
- #ウィズコロナ
- #CoE
- #SEO対策
- #UI改善
- #Web広告
- #テクノロジ・トレンド
- #ロボット活用
- #消費行動
- #アジャイル
- #ビジネスデザインスプリント
- #インフルエンサー
- #XR
- #VR
- #AR
- #MR
- #AI
- #アジャイル開発
- #プロダクトオーナー
- #アドテック東京
- #ビジネスフェア
- #BtoBオウンドメディア
- #異業種連携
- #銀行代理業
- #AI・IoT
- #医療・ヘルスケア
- #フードテック
- #パーソナライズ
- #リテールテックJAPAN
- #V-BALLER
- #プロダクトマネージャー
- #メンタリング
- #サービス共創
- #ギャンブル依存症
- #社会課題解決
- #Athena
- #マーケティングROI
- #MA
- #SCビジネスフェア
- #用語解説
- #組織変革
- #Marketing
- #奥谷孝司
- #マーケティングの新しい基本
- #顧客時間
- #VivaTech
- #メタバース・NFT
- #D2C